NTFS Index
NTFS에서는 자료들을 빠르게 검색할 수 있도록 인덱스 구조로 관리하고 있다. 대표적인 예로 디렉터리가 있다. 왜냐하면 디렉토리 구조는 $FILE_NAME을 포함하고 있기 때문이다. 공부를 해본 사람이라면 Hex Editor로 봤을 때 $I30이라는 것을 본 적이 있을 것이다. 그것이 하나의 예이다. Windows 2000이하는 오로지 인덱스에 $FILE_NAME만 사용됐었다. 하지만 지금은 여러 속성에 대해서 Index를 사용하고 있다. 다음은 NTFS가 관리하는 데이터표이다.

그러면 인덱스가 어떻게 구현되는지 알아봅시다
B-Trees
B-Tree라는 개념을 알아야 합니다. 파일시스템 뿐만 아니라 데이터베이스에서도 많이 사용 트리 자료구조의 일종입니다. 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조입니다.
방대한 양의 저장된 자료를 검색해야 하는 경우 검색어와 자료를 하나하나 비교하는 방식은 비효율적입니다. B-Tree는 자료를 정렬된 형태로 보관하여 시간을 단축합니다. 자세한건 B 트리 - 위키백과, 우리 모두의 백과사전 (wikipedia.org) 를 참고하자.
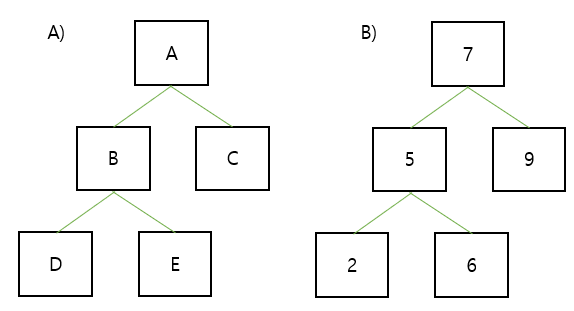
위 사진을 보면 상단 그림의 A트리를 보면 이진 트리 구조입니다. 상단 A노드는 노드 B, C와 연결이 됩니다. 그리고 노드 B는 노드 D, E에 연결이 됩니다. 즉, 상위 노드는 '다른 노드에 연결되는 노드'이고 하위 노드는 '연결된 노드'라고 할 수 있습니다. 그리고 리프(leaf) 노드라는 개념도 있습니다. 자식이 없는 노드를 leaf node(리프 노드)라고 합니다.
트리는 데이터를 쉽게 정렬하고 찾는 데 사용할 수 있기 때문에 사용합니다. 우측 B 트리를 봅시다. 각 노드에 한 개의 값들이 들어 있습니다. 예를 들어 '6'이라는 값을 찾고 싶다면 루트 노드를 보고 값이 크면 작으면 좌측, 크면 우측으로 이동하면 됩니다. 즉 6은 루트 노드보다 값이 적기 때문에 좌측 하위 노드로 이동하여 '5'와 비교를 합니다. 값이 크므로 우측 하위노드로 이동하여 6을 찾습니다.
간단한 예시를 이용했기 때문에 2진 트리로 보입니다. 하지만 NTFS는 하위노드를 꼭 2개를 가지지 않고 더 많이 가질 수 있습니다. 전형적으로, 위 예시에서는 각 노드는 하나의 값을 가지고 두 개의 하위 노드를 가질 수 있었습니다. 만약 값을 더 가질 수 있다면 하위노드도 더 많아질 것입니다. 이제 파일시스템적으로 예시를 보도록 합시다

Root Index노드 A에서는 세 개의 값과 네 개의 하위 노드들이 있습니다. 만약 우리가 iii.txt 파일을 찾고 싶다면 루트 노드의 값을 보고 이름이 알파벳 순으로 정렬되어있기 때문에 eee.txt와 iii.txt 사이를 찾을 것이다. 그 다음으로, 노드 C에서 또한 정렬된 알파벳을 보고 최종적으로 iii.txt파일을 찾게될 것이다. 그렇다면 값을 단순히 찾는 것이 아니라 어떻게 삭제되는지 알아보자.
NTFS에서 값이 어떻게 추가되고 삭제되는지에 대한 컨셉은 매우 중요합니다. 만약 노드당 3개의 파일 이름이 알맞다고 가정하고, jjj.txt를 추가하도록 하겠습니다. 그냥 추가하면 간단하겠지만, 두 개의 노드가 삭제되고 다섯 개의 노드가 생성됩니다. 우리가 jjj.txt가 어디에 위치해야 하는지 찾을 때 jjj.txt가 노드 C 끝인 iii.txt노드 다음에 있어야 한다는 것을 알 수 있다. 다음 그림은 jjj.txt가 추가된 상황이다. 하지만 한 노드에는 3개의 파일 이름만 올 수 있다고 했다.때문에 노드C를 분리하는 작업을 가져야 한다. 즉, 노드 C의 fff.txt와 ggg.txt를 한 단계 위로 올려야 할 필요가 있다.

다음 아래 사진은 각 노드를 분리한 상황입니다. 노드 C가 사라지고 ggg.txt는 상위로, fff.txt는 새로운 노드 F를 할당받았습니다. 근데 보면 노드 A는 값이 4개가 되어버렸습니다. 노드 C의 값을 없애려다 보니 결국 상위 노드에 값이 4개가 되었습니다. 그럴 땐, ggg.txt를 한 단계더 높여주도록 합시다.

최종적으로 jjj.txt를 추가했을 때의 결과는 다음과 같습니다. 그러면 삭제는 어떻게 진행이 될까요? 2개의 파일 이름을 가지는 노드 E의 zzz.txt를 삭제하도록 해봅시다.
단순히 노드 E에서 이름이 제거되고 다른 변경사항을 필요로 하지 않습니다. 구현에 따라 zzz.txt의 세부 정보가 달라집니다. 복구도 가능하죠.

더 복잡한 상황이 되려면 fff.txt가 삭제되어야 하는 것입니다. 그러면 노드 F는 빈 노드가 됩니다. 그 안을 우리는 채워주어야 하고요. 노드 I의 eee.txt파일을 노드 F로 옮겨주어야하고. 노드 B의 bbb.txt의 파일을 노드 I로 옮겨주어야 합니다. 이렇게 하면 모든 leaves이 노드 H로부터 동일한 거리에 있는 경우에도 균형 잡힌 트리를 만들 수 있습니다. 그래서 최종 결과는 아래 사진과 같게 됩니다.
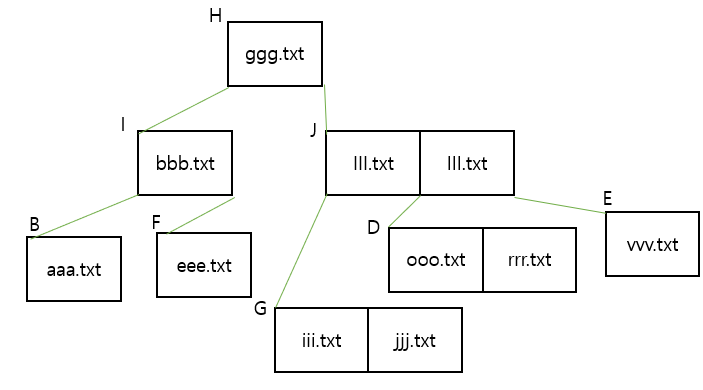
좀 더 깊게 들어가면, 노드 B는 bbb.txt를 포함하고 있는 상태입니다. 포렌식 도구를 활용해서 들여다보면 bbb.txt는 삭제될 것이라고 결과를 보여줄 수도 있지만, 사실상 그렇지 않습니다. 아까 예시에서 우리는 fff.txt를 삭제했으니깐요. 트리에서 값을 추가하고 삭제하는 과정은 복잡했습니다. 디렉터리의 이름 목록을 사용하는 FAT와 같은 파일 시스템을 사용하면 삭제된 이름이 존재하거나 존재하지 않는 이유를 쉽게 설명할 수 있지만, 트리에서는 결과를 예측하기 힘듭니다.
NTFS Index Attributes
위에까지가 일반적인 B-Tree의 개념이었습니다. 인덱스를 생성하기 위해서 NTFS에서는 B-Tree가 어떻게 구현되는지를 알아야 합니다. 트리의 각 엔트리는 노드안에 값을 저장하기 위해 사용되는 인덱스 엔트리라고 불리는 데이터 구조를 사용합니다. 인덱스 엔트리에는 여러가지 유형이 있지만, 표준 헤더 필드가 모두 동일합니다. 예를 들어 디렉토리 인덱스 엔트리에는 몇 개의 헤더와 $FILE_NAME 특성이 포함됩니다. 인덱스 엔트리는 트리의 노드로 구성되고 목록에 저장됩니다. 빈 엔트리는 끝 리스트에 시그널을 보내는데 사용됩니다. 아래에 $FIME_NAME 인덱스 항목이 4개인 디렉토리 인덱스 노드를 예로 들어봅시다. 다음은 인덱스 노드입니다.

인덱스 노드는 두 가지 유형의 MFT 엔트리 속성을 저장할 수 있습니다. $INDEX_ROOT 속성은 항상 Resident이며 오직 인덱스 트리의 적은 수를 포함하는 하나의 노드만 저장할 수 있습니다. 또한, $INDEX_ROOT 속성은 항상 인덱스 트리의 루트에 위치합니다.
인덱스가 클수록 Non-resident $INDEX_ALLOCATION 속성이 할당되며 이 속성은 필요한 만큼 얻을 수 있습니다. 이 속성의 내용은 하나 이상의 인덱스 레코드를 포함하는 더 큰 버퍼입니다. 인덱스 레코드는 고정된 값을 가지며(4096-byte), 인덱스 엔트리 리스트를 포함합니다. 각 인덱스 레코드는 0부터 시작하는 주소가 지정됩니다. 다음 아래의 사진에서 3개의 인덱스 엔트리를 가지는 $INDEX_ROOT 속성과 클러스터 713에 할당된 Non-resident인 $INDEX_ALLOCATION 속성이 있으며 3개의 인덱스 레코드를 사용하고 있는 것을 볼 수 있습니다.

$INDEX_ALLOCATION 속성은 인덱스 레코드에 사용되지 않는 공간을 할당할 수 있습니다. $BITMAP 속성은 인덱스 레코드의 할당상태를 관리하는데 사용됩니다. 트리에 새 노드를 할당해야 하는 경우 $BITMAP을 사용하여 사용가능한 인덱스 레코드를 찾고, 그렇지 않다면 더 많은 공간이 추가됩니다. 각 인덱스는 이름이 부여되고, $INDEX_ROOT, $INDEX_ALLOCATION, $BITMAP 속성은 속성 헤더에서 모두 동일한 이름이 할당됩니다.
추가예정
참고
Indexes | NTFS Concepts (flylib.com)
'DFIR > DFIR' 카테고리의 다른 글
| CVE-2020-1473 권한 상승 취약점 (1) | 2023.11.25 |
|---|---|
| 생성시간 및 수정시간 (0) | 2021.11.12 |
| [파일 시스템]NTFS - 4편(Resident, Cluster Run) (0) | 2021.11.12 |
| [파일 시스템]NTFS - 3편(Attributes, $속성들) (0) | 2021.11.12 |
| [파일 시스템]NTFS - 2편(MFT, Fixup array) (0) | 2021.11.12 |