Wireshark GUI를 통해서 대학 수업 등등 라이브로 패킷을 캡쳐해서 분석하는 등 활용이 많았지만 만약에 pcap 파일을 분석한다면? 사이즈가 적을 경우 흔히 더블클릭으로 파일을 열 수 있지만 사이즈가 점점 커질 수록 퍼포먼스가 느린 것을 느끼게 된다. 그럴 때 CLI 기반인 tshark라는 친구를 활용한다고 한다. 그러면 어떻게 쓰는지 간단히 알아보자.
<환경설정>
윈도우에서 tshark를 쓰기 위해서는 wireshark 설치경로를 환경변수로 설정해주어야 한다. 무조건은 아니지만 편하게 사용하기 위해서...
C:\Program Files\Wireshark 이 경로에 보통 설치되는 것 같다. 해당 폴더 안에tshark.exe 존재여부 확인 필요
디지털포렌식에서 네트워크를 볼 필요가 있을까? 라는 질문은 너무 무의미한 것 같다.
그러면 네트워크 포렌식은 왜 필요할까?
- 사이버범죄의 지능화 및 고도화 - Fileless 악성코드 등장으로 저장매체에 대한 분석만으로는 범죄의 입증 및 범인 추적이 어려워지고 있다. - 메모리 분석과 더불어 디스크 포렌식의 한계를 극복하는데 큰 도움이 된다. (ex. 아동음란물 비트코인 거래 등 범죄의 해결)
네트워크 포렌식 필요 사항
- 통신비밀보호법과 형사소송법에 따른 절차 - 패킷 감청 관련 판례 - TCP/IP 네트워크 통신에 대한 기본 지식 - 네트워크 패킷 분석도구 종류 및 사용법
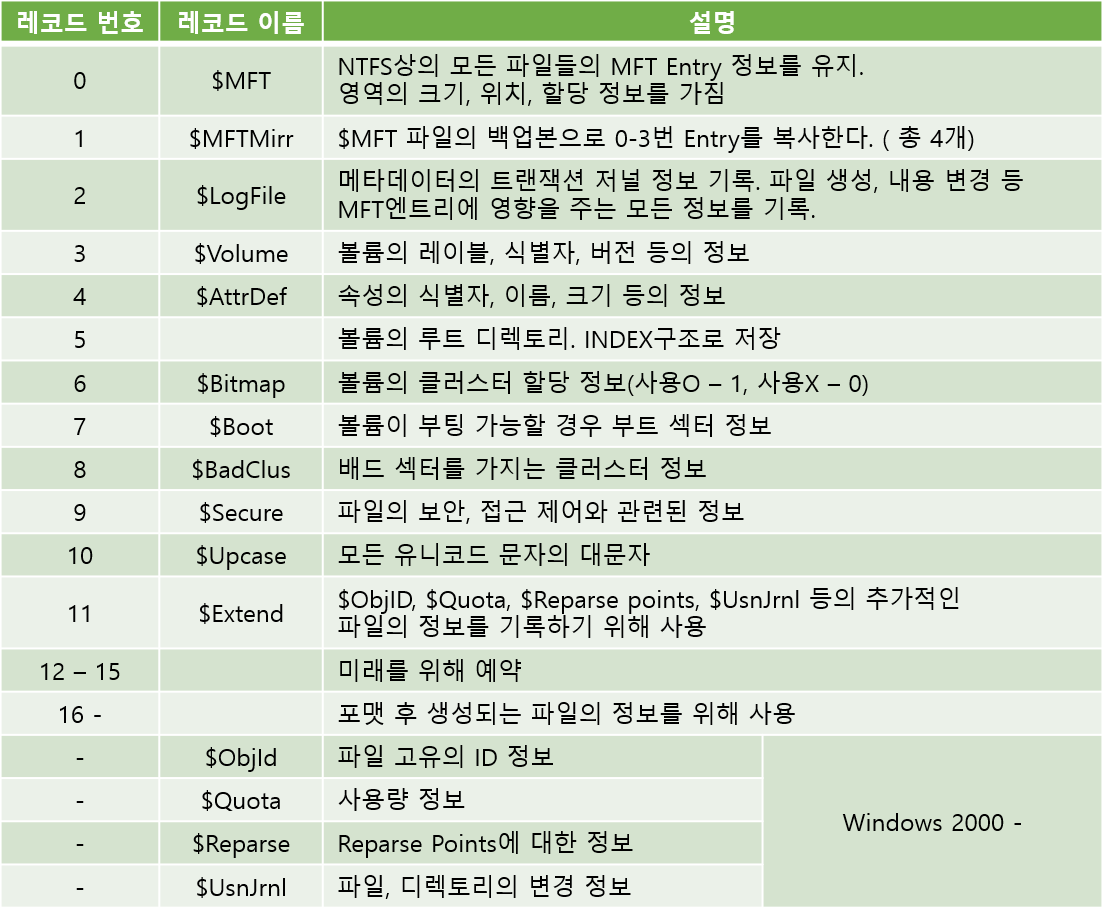
NTFS에서는 자료들을 빠르게 검색할 수 있도록 인덱스 구조로 관리하고 있다. 대표적인 예로 디렉터리가 있다. 왜냐하면 디렉토리 구조는 $FILE_NAME을 포함하고 있기 때문이다. 공부를 해본 사람이라면 Hex Editor로 봤을 때 $I30이라는 것을 본 적이 있을 것이다. 그것이 하나의 예이다. Windows 2000이하는 오로지 인덱스에 $FILE_NAME만 사용됐었다. 하지만 지금은 여러 속성에 대해서 Index를 사용하고 있다. 다음은 NTFS가 관리하는 데이터표이다.
그러면 인덱스가 어떻게 구현되는지 알아봅시다
B-Trees
B-Tree라는 개념을 알아야 합니다. 파일시스템 뿐만 아니라 데이터베이스에서도 많이 사용 트리 자료구조의 일종입니다. 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조입니다.
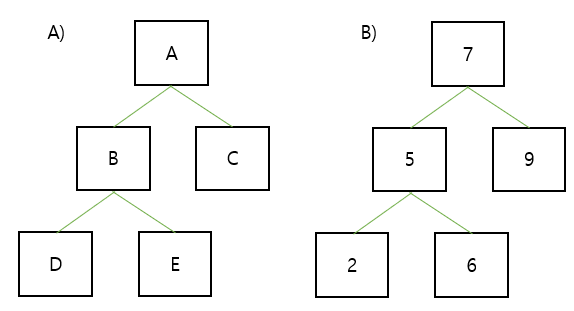
위 사진을 보면 상단 그림의 A트리를 보면 이진 트리 구조입니다. 상단 A노드는 노드 B, C와 연결이 됩니다. 그리고 노드 B는 노드 D, E에 연결이 됩니다. 즉, 상위 노드는 '다른 노드에 연결되는 노드'이고 하위 노드는 '연결된 노드'라고 할 수 있습니다. 그리고 리프(leaf) 노드라는 개념도 있습니다. 자식이 없는 노드를 leaf node(리프 노드)라고 합니다.
트리는 데이터를 쉽게 정렬하고 찾는 데 사용할 수 있기 때문에 사용합니다. 우측 B 트리를 봅시다. 각 노드에 한 개의 값들이 들어 있습니다. 예를 들어 '6'이라는 값을 찾고 싶다면 루트 노드를 보고 값이 크면 작으면 좌측, 크면 우측으로 이동하면 됩니다. 즉 6은 루트 노드보다 값이 적기 때문에 좌측 하위 노드로 이동하여 '5'와 비교를 합니다. 값이 크므로 우측 하위노드로 이동하여 6을 찾습니다.
간단한 예시를 이용했기 때문에 2진 트리로 보입니다. 하지만 NTFS는 하위노드를 꼭 2개를 가지지 않고 더 많이 가질 수 있습니다. 전형적으로, 위 예시에서는 각 노드는 하나의 값을 가지고 두 개의 하위 노드를 가질 수 있었습니다. 만약 값을 더 가질 수 있다면 하위노드도 더 많아질 것입니다. 이제 파일시스템적으로 예시를 보도록 합시다
Root Index노드 A에서는 세 개의 값과 네 개의 하위 노드들이 있습니다. 만약 우리가 iii.txt 파일을 찾고 싶다면 루트 노드의 값을 보고 이름이 알파벳 순으로 정렬되어있기 때문에 eee.txt와 iii.txt 사이를 찾을 것이다. 그 다음으로, 노드 C에서 또한 정렬된 알파벳을 보고 최종적으로 iii.txt파일을 찾게될 것이다. 그렇다면 값을 단순히 찾는 것이 아니라 어떻게 삭제되는지 알아보자.
NTFS에서 값이 어떻게 추가되고 삭제되는지에 대한 컨셉은 매우 중요합니다. 만약 노드당 3개의 파일 이름이 알맞다고 가정하고, jjj.txt를 추가하도록 하겠습니다. 그냥 추가하면 간단하겠지만, 두 개의 노드가 삭제되고 다섯 개의 노드가 생성됩니다. 우리가 jjj.txt가 어디에 위치해야 하는지 찾을 때 jjj.txt가 노드 C 끝인 iii.txt노드 다음에 있어야 한다는 것을 알 수 있다. 다음 그림은 jjj.txt가 추가된 상황이다. 하지만 한 노드에는 3개의 파일 이름만 올 수 있다고 했다.때문에 노드C를 분리하는 작업을 가져야 한다. 즉, 노드 C의 fff.txt와 ggg.txt를 한 단계 위로 올려야 할 필요가 있다.
다음 아래 사진은 각 노드를 분리한 상황입니다. 노드 C가 사라지고 ggg.txt는 상위로, fff.txt는 새로운 노드 F를 할당받았습니다. 근데 보면 노드 A는 값이 4개가 되어버렸습니다. 노드 C의 값을 없애려다 보니 결국 상위 노드에 값이 4개가 되었습니다. 그럴 땐, ggg.txt를 한 단계더 높여주도록 합시다.
최종적으로 jjj.txt를 추가했을 때의 결과는 다음과 같습니다. 그러면 삭제는 어떻게 진행이 될까요? 2개의 파일 이름을 가지는 노드 E의 zzz.txt를 삭제하도록 해봅시다.
단순히 노드 E에서 이름이 제거되고 다른 변경사항을 필요로 하지 않습니다. 구현에 따라 zzz.txt의 세부 정보가 달라집니다. 복구도 가능하죠.
zzz.txt 삭제
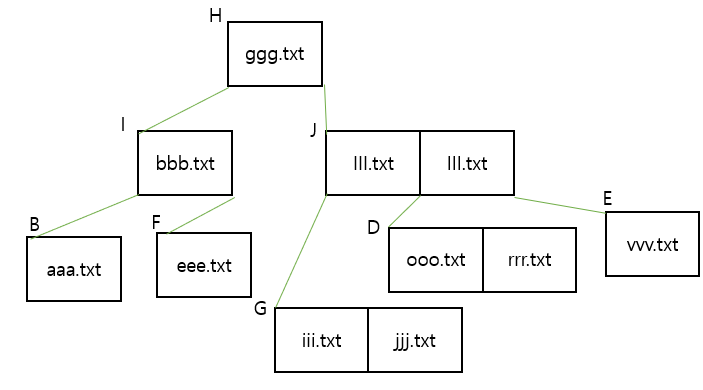
더 복잡한 상황이 되려면 fff.txt가 삭제되어야 하는 것입니다. 그러면 노드 F는 빈 노드가 됩니다. 그 안을 우리는 채워주어야 하고요. 노드 I의 eee.txt파일을 노드 F로 옮겨주어야하고. 노드 B의 bbb.txt의 파일을 노드 I로 옮겨주어야 합니다. 이렇게 하면 모든 leaves이 노드 H로부터 동일한 거리에 있는 경우에도 균형 잡힌 트리를 만들 수 있습니다. 그래서 최종 결과는 아래 사진과 같게 됩니다.
fff.txt 삭제
좀 더 깊게 들어가면, 노드 B는 bbb.txt를 포함하고 있는 상태입니다. 포렌식 도구를 활용해서 들여다보면 bbb.txt는 삭제될 것이라고 결과를 보여줄 수도 있지만, 사실상 그렇지 않습니다. 아까 예시에서 우리는 fff.txt를 삭제했으니깐요. 트리에서 값을 추가하고 삭제하는 과정은 복잡했습니다. 디렉터리의 이름 목록을 사용하는 FAT와 같은 파일 시스템을 사용하면 삭제된 이름이 존재하거나 존재하지 않는 이유를 쉽게 설명할 수 있지만, 트리에서는 결과를 예측하기 힘듭니다.
NTFS Index Attributes
위에까지가 일반적인 B-Tree의 개념이었습니다. 인덱스를 생성하기 위해서 NTFS에서는 B-Tree가 어떻게 구현되는지를 알아야 합니다. 트리의 각 엔트리는 노드안에 값을 저장하기 위해 사용되는 인덱스 엔트리라고 불리는 데이터 구조를 사용합니다. 인덱스 엔트리에는 여러가지 유형이 있지만, 표준 헤더 필드가 모두 동일합니다. 예를 들어 디렉토리 인덱스 엔트리에는 몇 개의 헤더와 $FILE_NAME 특성이 포함됩니다. 인덱스 엔트리는 트리의 노드로 구성되고 목록에 저장됩니다. 빈 엔트리는 끝 리스트에 시그널을 보내는데 사용됩니다. 아래에 $FIME_NAME 인덱스 항목이 4개인 디렉토리 인덱스 노드를 예로 들어봅시다. 다음은 인덱스 노드입니다.
인덱스 노드는 두 가지 유형의 MFT 엔트리 속성을 저장할 수 있습니다. $INDEX_ROOT 속성은 항상 Resident이며 오직 인덱스 트리의 적은 수를 포함하는 하나의 노드만 저장할 수 있습니다. 또한, $INDEX_ROOT 속성은 항상 인덱스 트리의 루트에 위치합니다.
인덱스가 클수록 Non-resident $INDEX_ALLOCATION 속성이 할당되며 이 속성은 필요한 만큼 얻을 수 있습니다. 이 속성의 내용은 하나 이상의 인덱스 레코드를 포함하는 더 큰 버퍼입니다. 인덱스 레코드는 고정된 값을 가지며(4096-byte), 인덱스 엔트리 리스트를 포함합니다. 각 인덱스 레코드는 0부터 시작하는 주소가 지정됩니다. 다음 아래의 사진에서 3개의 인덱스 엔트리를 가지는 $INDEX_ROOT 속성과 클러스터 713에 할당된 Non-resident인 $INDEX_ALLOCATION 속성이 있으며 3개의 인덱스 레코드를 사용하고 있는 것을 볼 수 있습니다.
$INDEX_ALLOCATION 속성은 인덱스 레코드에 사용되지 않는 공간을 할당할 수 있습니다. $BITMAP 속성은 인덱스 레코드의 할당상태를 관리하는데 사용됩니다. 트리에 새 노드를 할당해야 하는 경우 $BITMAP을 사용하여 사용가능한 인덱스 레코드를 찾고, 그렇지 않다면 더 많은 공간이 추가됩니다. 각 인덱스는 이름이 부여되고, $INDEX_ROOT, $INDEX_ALLOCATION, $BITMAP 속성은 속성 헤더에서 모두 동일한 이름이 할당됩니다.
본 포스팅에서는 Resident, Non-Resident, Cluster Run을 다룰 예정입니다.
- Resident, Non-resident - Cluster Run
NTFS구조
지난 시간에 이어 NTFS 구조와 MFT 엔트리 구조를 보겠습니다.
이 그림을 보고 간단하게 설명하고 넘어갈 수 있으면 좋겠습니다. 그럼 Resident와 Non-resident를 알아보도록 하겠습니다.
Resident & Non-resident 속성 헤더
Resident 속성은 속성의 내용이 속성 헤더 바로 뒤에 위치 합니다. 하지만 Non-resident는 크기가 커서 MFT 엔트리 1,024바이트 내에 있지 못하고 따로 클러스터를 할당 받아 저장하는 방식입니다. 당연히 속성 내용 위치에는 할당 받은 클러스터의 위치 정보가 저장되어 있습니다. 대부분의 속성은 모두 Resident 속성이고, $DATA, $ATTRIBUTE_LIST와 같은 속성은 Non-resident가 될 수 있습니다. $DATA는 파일의 내용을 표현하는 속성이라고 했습니다. 내용이 MFT 엔트리 내에 저장될 만큼의 용량이 아니라면 Non-resident 속성이 됩니다.
$ATTRIBUTE_LIST속성은 속성 내용이 많아서 하나의 MFT 엔트리에 담지 못하는 경우, 여러 개의 엔트리를 사용하게 되는데, 이때 흩어진 각 속성들의 정보를 저장하는 속성이다. 이 속성 또한 내용이 커지면 Non-resident가 된다.
Cluster Runs(클러스터 런)
속성이 Non-resident일 경우 별도의 클러스터를 할당 받아서 내용을 저장한다고 했다. 비연속적인 공간들을 효과적으로 관리하기 위한 것이 클러스터 런인 것이다. 이러한 클러스터 런들은 런리스트(Runlist) 형태로 관리가 된다. 클러스터 크기는 파일의 크기에 따라 당연히 천지차이일 것이다.
그러면 클러스터 런을 직접 USB가지고 테스트 해봅시다. 파일 명은 cluster2_run.txt 입니다.
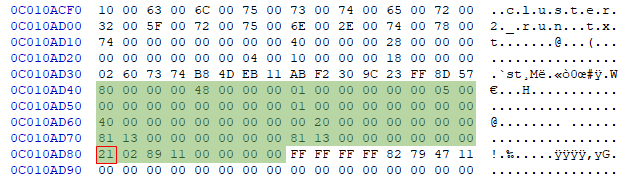
초록색은 첫 번째 줄은 $DATA 속성 식별 값을 볼 수 있고, 8바이트 후에 Non-resident flag가 1로 설정되어있으므로 이 파일은 Non-resident 속성임을 알 수 있습니다. 맨 아래로 내려와서 빨간색 네모를 보시면21이라고 적혀있습니다. 이 21의 의미는2-byte의 런 오프셋과1-byte의 런 길이라는 뜻입니다.
위의 의미를 해석해보자. 0x02( 2 ) 개의 클러스터가 오프셋 0x1189(4489)부터 이 파일을 위해 할당되어 있다는 뜻이다. 그러면 실제로 해당 위치에 데이터가 있는지 확인하여 보자.
클러스터는 총 2개 8KB를 할당 받았다. 오프셋을 보면 4489클러스터 크기를 가진다. 1클러스터는 8섹터 이므로 4489 * 8 = 35912 섹터가 나오고 VBR위치가 2048부터 시작이므로 마지막으로 35912 + 2048 = 37960 섹터가 나온다. 이동해보자.
NTFS의 기본 구조는 아래와 같습니다. VBR, MFT. Data Area로 이루어져 있는 것을 다시 한 번 상기시켜보도록 합시다.
1편에서 VBR에 대해서 다뤘으며, VBR은 Boot Sector와 NTLDR로 이루어져 있었습니다. 또한, 최종적으로 NTFS복원까지도 해봤습니다. VBR은 단지 부팅을 위한 영역이다. 오늘 2편에서 다룰 내용은 MFT입니다. VBR다음에 MFT가 바로 붙어있는 사진이 있지만 사실상 물리적으로 떨어져 있습니다. 또한 MFT는 VBR이후 모든 볼륨 영역 아무곳에나 위치할 수 있습니다.
MFT란
MFT 엔트리 0번은 $MFT파일을 가리킨다. $MFT파일은 MFT영역 자체의 정보를 가지고 있다. MFT파일의 메타 정보를 유지하고 있는 엔트리이다. $MFT엔트리 정보를 읽으면 전체 MFT가 할당하고 있는 클러스터 정보를 얻을 수 있다. 즉, NTFS에 접근할 때 부트 섹터의 정보를 이용하여 $MFT엔트리 정보를 얻게된다면 전체 MFT영역의 레이아웃을 알아낼 수 있다. 다시말해서 NTFS내에 존재하는 파일 및 디렉토리의 메타 정보를 얻을 수 있다. 메타 정보는 파일 이름, 생성 시간, 수정시간, 크기 등을 말한다. $MFT도 하나의 파일이며, 시간 정보, 용량이 표시된다. MFT 엔트리를 살펴보자. 아래 사진을 보면 0번은 $MFT로 시작하게 된다.
MFT레코드는 총 1024바이트이며, 포맷만 해도 생성되는 파일들도 있다. 또한 앞에 15개는 예약되어 있으며 모두 '$'를 맨 앞에 두고있다. $LogFile에서는 R,WWW를 하게 되면 하나의 트랜잭션이 생성된다. 하지만 중간에 PC가 off가 된다면 Check Disk가 뜨게 된다. 이를 롤백이라고 하고, 저널링이라고도 한다. 레지스트리 또한 저널링을 사용한다. $UsnJrnl은 $LogFile과 합쳐서 파일 시스템 로그라고 부른다.
디지털 포렌식 관점
용량이 커지면 커질수록 이미징 하는데 시간이 너무 오래 걸리게 된다. 그렇다면 복제나 이미징이 끝날 때까지 시간을 허비하고 있을 수는 없다. 일반적으로 신고부터 영장발부까지 48시간 내에 이루어져야 한다고 한다. 읽고, 쓰는 작업이 느리면 하루가 넘어갈 수도 있는데 그러면 48시간의 절반을 허비하고 그 남은 시간동안 증거를 찾아내야만 한다. 따라서, 이럴 경우 전체 데이터를 복제 및 이미징을 하기 보다는 MFT 영역만을 이미징하여 분석하는 방안이 필요하다. MFT 영역은 파일시스템에 존재하는 모든 파일 및 폴더에 대한 메타 정보를 가지고 있다. 메타 정보는 파일 이름, 숨긴 파일, 암호화, 시간 속성 등 의심되는 것들을 확인할 수 있다.
또한, MFT는 조각나있다고 한다. 처음 사용자가 파일을 몇 개 사용할지 모르기 때문이다. MFT구조 크기는 생성 파일, 폴더의 개수의 따라 차이가 난다. 실제로 물리적으로 2~3개로 조각나있다고 한다. 그러면 MFT 엔트리 구조에 대해서 알아보도록 하자.
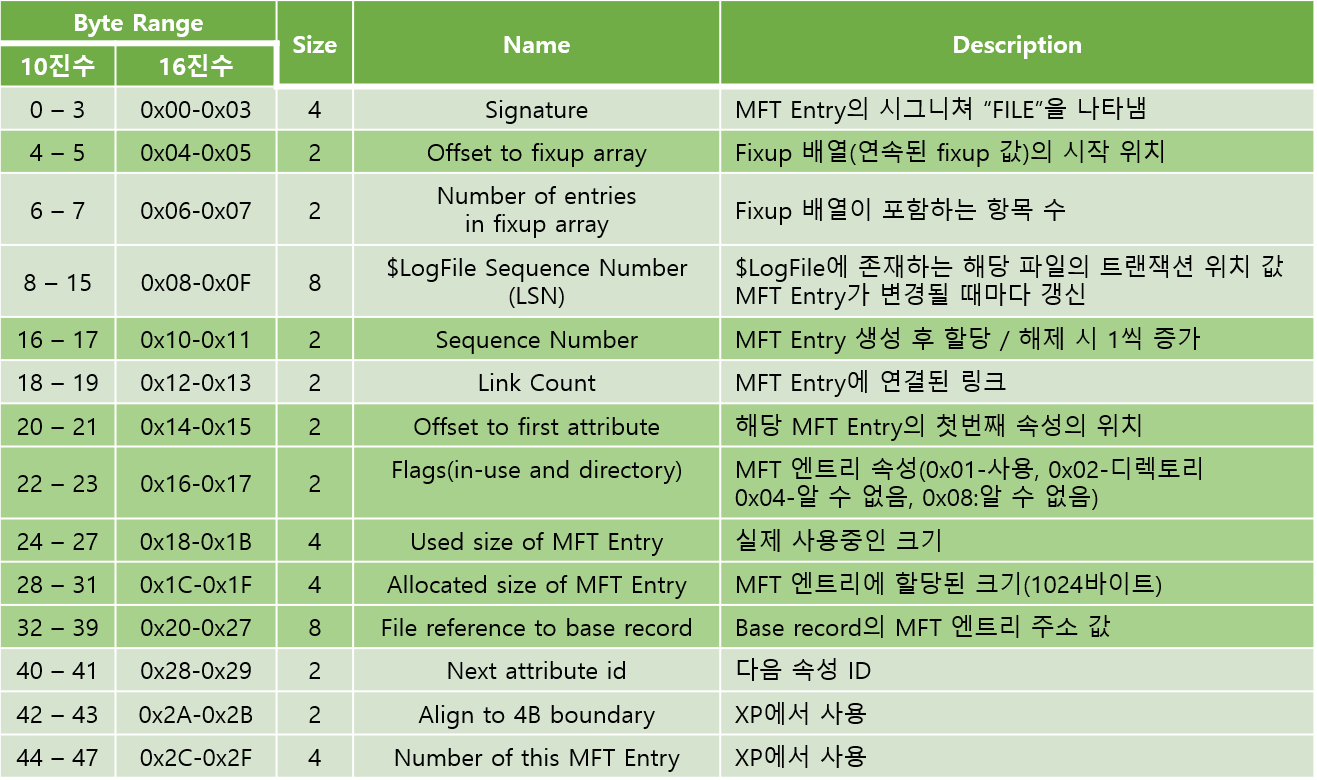
MFT 엔트리 구조
48바이트 크기의 MFT Entry Header 다음으로 Fixup, Attribute가 위치한다. 가운데에 위치한 속성은 파일이 일반 파일, 링크 파일, 비트맵 파일 등 파일 종류에 따라서 MFT엔트리에 존재하는 속성들이 다르다. Attribute안에도 여러 세부적인 정보로 나뉘어진다. 그 다음으로 속성의 끝을 알려주는 표시가 온다. 그 다음으로는 MFT에서는 사용하지 않는 영역이 배치되어 있다.
MFT Entry Header
MFT 엔트리 헤더는 MFT 엔트리의 앞 48바이트의 정보를 나타낸다. 중요한 값은 좀 더 진한 녹색으로 표시를 했다.
참고로 MFT 엔트리를 모아둔 파일을 $MFT라고 했습니다. $MFT역시 하나의 파일이므로 $MFT파일의 내용 중 일부가 아닌 $MFT파일 자체가 MFT 엔트리입니다.
그러면 실습 USB를 가지고 MFT엔트리 헤더를 구경해봅시다. 모든 색상을 색칠하지 않고 구간별로만 나눠서 보기 편하게 했습니다.
Sequence Number: 0x0001 부모 식별을 위해 기록한다. 특정 행위시마다 +1증가. MFT헤더에 기록.
Link Count : 0x0001
Offset to first attribute : 0x0038
Flags: 0x0001
Used size of MFT entry : 0x000001B0
Allocated sie of MFT entry : 0x00000400 (1024바이트)
File reference to base record : 0x00000000 00000000
Next attribute id : 0x0007
Align to 4B boundary : 0x0000
Number of this MFT Entry : 0x00000000
Flag
Flag는 레코드가 사용 중인지 삭제된 것인지에 대한 여부를 표시하기도 한다. 사용중인 디렉토리라면 0x03, 지워지면 0x00을 나타낸다. 즉, Flag가 0이거나 2면 지워진 파일이나 폴더를 나타낸다.
Fixup Array
Fixup이라는 것은 그 자체로 "고치다" 라는 의미를 가진다. 파일시스템에서 "고친다"라는 것은 신뢰성을 높이기 위함이라고 볼 수 있다. MFT 엔트리는 1,024바이트 총 2섹터를 사용하는데, NTFS를 구성하는 데이터가 하나 이상의 섹터를 사용할 경우 섹터의 마지막 2바이트 값을 별도로 지정하고, 해당 위치에는 Fixup값 2바이트가 들어간다. 만약 섹터의 내용이 비정상적으로 변경될 때, 데이터 해석하기 전 등 오류를 사전에 찾아낼 수 있다.
위 예시를 보면 Fixup array가 위치한 곳은 0x30이라고 나타내고 있다. 0x30 위치에는 0x014A라는 값이 들어있다. 그리고 Number of entries in fixup array값이 0x0003이다. 이 값은 기본적으로 3이다. 3*2(총 6바이트)가 Fixup값에 의해 대체된 값을 저장하는 배열이 되는데, 이 3이라는 것은 MFT 엔트리가 2개의 섹터를 사용하므로 MFT 엔트리 내에 존재하는 섹터의 마지막 2바이트와 추가적으로 하나를 더 예비해 둔 것이다. MFT 엔트리를 더 많이 사용한다면 그 숫자도 증가할 것이다.
보호된 fixup record를 읽기 전 과정
1. Update Sequence Number에 하나를 추가한다(0x0000은 건너뛰어야 함) 2. 각 섹터에 대해 마지막 2바이트를 Update Sequence Array에 복사한다. 3. 각 섹터 끝에 Update Sequence Number번호를 기록한다. 4. 마지막으로 디스크에 기록한다.
디스크에서 record 읽는 과정
1. magic number가 정확한지 확인해야 한다. 2. Update Sequence Number를 읽는다. 3. 모든 섹터의 마지막 2바이트와 비교한다. 4. 정확한 위치에 Update Sequence Array에 내용을 복사한다.
읽을 때 하나라도 실패하면 배드 섹터 및 디스크 손상, 드라이버 결함이 있을 수 있다.
MFT Record 이외에 Fixup Array를 사용하는 구조는 다음과 같다.
- 폴더와 인덱스의 INDX Record - $LogFile의 RDRD Record - $LogFile의 RSTR Record
모든 데이터는 파일 형태로 관리되며, VBR의 위치는 고정되어 있다. MFT의 시작은 일반적으로 VBR이후지만, 크기가 커지면서 데이터 영역에 추가로 할당되기도 한다. 참고로, NTFS는 N번 클러스터 * SPC하면 섹터위치로 이동한다. MBR ~ MBR slack : ROM BIOS가 사용한다(섹터 단위). 클러스터는 OS 포맷할 때 쓴 것.
VBR(Volume Boot Record)
NTFS VBR의 구조는 다음과 같습니다. NTFS는 클러스터 단위를 사용한다고 했었습니다. VBR도 할당될 때 기본 클러스터 크기만큼(512) 할당이 됩니다. 보통 4K이므로 8개 섹터를 할당 받습니다.
OEM ID(제조사 식별 값) : NTFS라고 표시. 가상 VMDK VBR도 나오곤 한다. 값이 바뀌면 마운트가 되지 않으니 수정하지 말 것. 문자열 NTFS검색으로도 찾아도 된다(하지만 무조건 부트섹터에 있는 것만은 아님). 정확도를 높이고자 하면 Jump Instruction 포함 11바이트 검색하면 정확도는 높아진다.
BIOS Parameter Block(BPB)
보통 BPB면 Bytes Per Sector부터 시작하지만 FAT에서도 그랬듯이 Jump Instruction부터 다 포함시켰다. 위 사진에는 봐야할 곳만 색칠을 해놓았다. Total Sectors는 4바이트에서 8바이트로 늘어났다. $MFT는 NTFS에서 제일 중요하다. 중요하다보니 $MFTMirr로 백업본을 두지 않았나 싶다. 모든 파일 및 폴더 정보를 가지고 있기 때문이다. 이 구조만 알면 모든 파일 테이블의 정보를 다 알 수 있다. 또한, BPB에서 중요하게 봐야될 정보는 Start Cluster for MFT 필드이다.
Bytes Per Secotr(BPS) : 보통 512 Sector Per Cluster : 보통 8(1 클러스터당 8섹터) Reserced Sectors : NTFS는 없음(NTFS는 항상 파티션 맨 앞에 부트 섹터가 존재) Media Description : 0xF8(고정식 디스크), 나머지 값은 플로피디스크 구분 Total Sectors : 해당 볼륨이 가지는 총 섹터 수 Start Cluster for $MFT : $MFT의 LBA 주소 Start Cluster for $MFTMirr : $MFTMirr의 LBA주소 Clusters Per MFT Record : MFT Record 크기, MFT Record는 MFT레코드의 묶음이다. Cluster Per Index Buffer : 폴더 구조에서 사용되는 인덱스 버퍼의 크기 Volume Serial Number : 볼륨 시리얼 번호(포맷 때 마다 변경).
MFT Record : NTFS의 모든 파일은 반드시 하나의 MFT 레코드를 가진다. MFT Record로 자기 자신의 메타 정보를 표현한다.
그렇다면 이제 MFT 시작위치를 따라가볼까요? FAT편을 보고 오신 분은 물리디스크로 열어서 실습을 했었는데요, 이번에는 논리디스크로 열어서 실습하도록 하겠습니다.
MFT 클러스터 시작은 0x0C0000 클러스터부터 시작이군요. 섹터단위가 아니라서 한 번 더 계산을 해주어야 합니다. 1클러스터는 8섹터라고 했었죠? 0x0C0000 * 8을 해주면 0x600000(6,291,456)섹터가 됩니다. 만약 바이트로 넘어가고 싶다면 8섹터는 4096(0x1000)바이트이므로 0x0C0000 * 0x1000 = 0xC0000000(3,221,225,472) 값으로 이동하시면 됩니다. 아래 표를 참고해주세요. 원하시는 단위로 계산하시고 이동해주시면 됩니다. 물론 논리로 열었을 때 입니다. 물리로 여셨으면 기존 VBR위치를 더해주셔야 합니다.
위와 같이 계산하고 이동하시면 결과는 아래와 같습니다. 이 구조만 살아있다면 100% 복구가 가능합니다. 이 구조가 없다면 손상된 것이죠. 손상안된 부분만 복구가 가능하고, 나머지는 카빙해야 합니다. $MFT는 MFT 레코드의 연속이라고 했습니다. MFT 레코드의 시그니처는 FILE 이다. FILE을 시작으로 1024바이트(2섹터) 만큼 점프하면 FILE이 또 나온다. 이들을 묶은 것을 $MFT라고 한다.
좌(첫 FILE), 우(1024바이트 후)
그렇다면 MFTMirr는 어디에 있을까? BPB에서 MFT다음 8바이트가 MFTMirr 위치였다. MFTMirr의 값은 0x02이므로 섹터로 계산하면 8을 곱해주어야 한다. 즉 16섹터로 이동하면 된다.
MFTMirr는 MFT수 만큼 다 백업하지 않는다. MFT 위치가 0x0C0000으로 거의 고정되는 것처럼 MFTMirr도 특별한 이유가 없으면 2번째 클러스터에 위치한다. MFTMirr도 1024바이트 만큼 뒤에 반복적으로 4개가 나온다.
MFTMirr는 $MFT의 가장 앞쪽의 하나의 클러스터만 백업한다(4096바이트 - 4K). 제일 중요한 것은 MFT의 첫 레코드이기 때문이다.
NTFS VBR 복원
VBR-BS가 손상된 경우
백업 BS 존재 하는 경우
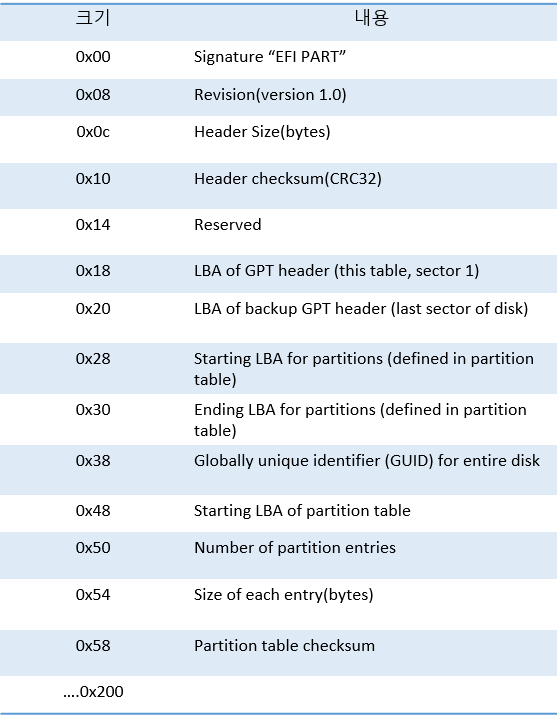
VBR-BS가 손상되었을 경우 볼륨 끝 백업 BS를 활용해준다. 백업 BS는 볼륨 마지막 섹터에 있으니 찾아가면 된다. 그러면 찾아가는 방법을 안내하고자 한다. 파티션 테이블 구조에서 마지막 4바이트가 크기인 것을 기억해야 한다.([Digital Forensic] MBR이란? (tistory.com)) 필자의 DOTAKY99의 파티션 테이블은 아래와 같다.
다시 설명하자면, VBR 위치에서 LBA 총 섹터 수 더하고 -1을 해주면 백업 BS가 나온다. 복사하여 그대로 붙여넣어주면 복구가 된다. 하지만 망치려고 하는 나쁜 사람들이 백업이 있다는 정보를 모르진 않을 것이다.
결론적으로 VBR BS 백업을 찾았으면 그대로 덮어써주면 복원이 된다. 중요한 부분은 백업 BS가 없을 때 이다.
백업 BS가 존재하지 않는 경우
이럴 때는 볼륨 내 BS를 검색해보는 방법을 가져야 한다. 사이즈가 크면 클수록 시간이 오래걸린다. 검색은 Jump Instruction부터 OEM ID를 포함시켜 검색하여 준다(EB 52 90 4E 54 46 53 20). 또는 직접 값을 필드에 하나하나 넣어주는 수동으로 복원하는 방법도 있다.
FAT32복원 글을 보신 분은 아시겠지만, NTFS도 마찬가지로 모든 필드를 다 채워줄 필요가 없습니다. 핵심만 잘 수동으로 입력해주면 FKT에서 마운트가 됩니다. 복구할 필드는 다음과 같습니다.
OEM ID : NTFS입니다. FAT32는 MSDOS5.0이었고, exFAT은 "EXFAT"입니다! Bytes Per Sector : 보통 512(0x200) 입니다. Secotors Per Cluster : 2GB이상 볼륨의 기본 클러스터 크기는 4096-byte입니다. Total Sectors : 각 볼륨 구간을 식별하여 할당해주어야 합니다(BS탐색). Start Cluster for $MFT : VBR이후 "FILE" 시그니처 검색하여 $MFT위치를 알아내야 합니다. Start Cluster for $MFTMirr : $MFT와 같은 방법으로 찾아주시면 됩니다.Clusters(Bytes) Per File Record : 항상 F6(-10) 2의 10승 = 1024-byte입니다. FF가 -1로 표시 되므로 F6은 -10이 됩니다!
STEP 0 - VBR 위치 찾기
파티션 테이블에 의하면 128번 섹터에 위치하고 있다고 합니다. 백업 BS를 찾으려고 했지만 VBR위치 + 해당 파티션 크기 -1을 해도 백업본은 보이지 않습니다..!
다음은 NTFS라고 적혀 있어야 하는 곳이 말끔하게 비워져 있습니다. 이제부터 하나하나 채워나가 봅시다.
STEP 1 - OEM ID, Bytes Per Sector, Sector Per Cluster 채우기
OEM ID는 0x03~0x0A까지 채웠으며, BPS는 512바이트(0x200) 값으로 채웠고, SPC는 4096바이트 즉, 클러스터당 8섹터를 잡아먹고 있기 때문에 0x08로 채웠습니다. Reserved 는 안쓰니 당연히 0입니다.
STEP 2 - Start Cluster for $MFT, $MFTMirr 위치 찾기, Clusters Per MFT Record(F6)
$MFTMirr는 보통 2번 클러스터에 있다고 했습니다. 즉, 0x02 * 8섹터를 해주면 16섹터가 나오고, 기존 128섹터 위치에 더해주면 144섹터가 나옵니다. 이렇게 $MFTMirr도 확인해주실 수 있습니다. 한 번더 검색을 해봅시다.
MFT Mirr 위치
$MFTMirr의 첫 레코드는 $MFT 첫 부분과 같을 것이라 생각하여 아래 해당 값을 검색하여 329168섹터를 찾아냈습니다. 기존 BS위치를 빼줘야 하므로 329,168 - 128 = 329,040이 나오며 여기서 나누기 8을 해주면 클러스터 값이 됩니다. 즉, Start Cluster for $MFT는 0xA0AA값이 나오게 됩니다.
NTFS 복원 과정
마지막으로 Clusters Per MFT Record 값인 F6을 넣어주면 다음과 같이 마무리가 됩니다.
절전 모드 전환에는 또 두 가지 경우로 나뉜다. 시작버튼에서 절전모드 하는 방식과 흔히 ALT-F4를 눌러서 절전모드를 누르는 경우이다. 실험 PC에서는 같은 로그를 띄웠다. 사용자가 직접 절전모드를 눌렀을 때는 다음과 같은 로그가 발생한다. ( 추후 더 다양한 환경에서 해볼 예정 )
아래는 최대 절전모드를 사용자가 직접 누를 때 나타나는 로그이다. TargetState, EffectiveState값이 5로 설정되어있다.
CASE2 - 사용자가 PC를 사용하지 않아서 절전모드 혹은 최대 절전모드로 전환될 때
사용자의 PC 미사용으로 인한 절전모드 전환이다. TargetState, Effective 값은 4로 고정이며, Reason은 7로 표시된다.
<최대 절전모드 추후 게시>
CASE3 - 노트북 경우 화면을 닫는 경우
노트북 뚜껑을 닫는 경우 다음과 같은 로그가 발생한다. TargetState, EffectiveState값이 4, Reason은 0으로 표시된다. 아래 로그는 일반 절전 모드일 때 뚜껑을 닫은 로그이다.
다음 아래 로그는 최대 절전 모드 설정 후 뚜껑을 닫아보았다. TargetState, EffectiveState값이 달라졌다.
CASE4 - 그 외
TargetState 값이 6, EffectiveState 값이 5, Reason이 4일 때의 경우도 나오는데 아직 정보가 확실하지 않다. 하지만 확실한건 사용자가 절전모드를 누르지 않고 생긴 로그이다. 추후 분석요함.
포렌식 관점에서 시스템 시간 변경 행위는 중요하다. 하지만 시스템 자체에서 시간을 자동적으로 맞추는 기능과 사용자가 직접 시간대를 변경한 행위를 구분지어야한다. 시간 변경으로 행위를 감추려는 흔적을 의심할 수 있기 때문이다.
아래 CASE1, 2는 프로젝트를 진행하면서 사용자와 시스템 사이에서 어떤 로그가 또는 어떤 로그를 같이봐야 사용자가 수동으로 시스템 시간을 변경한 것인지에 대해 실험을 해보았다.
CASE1
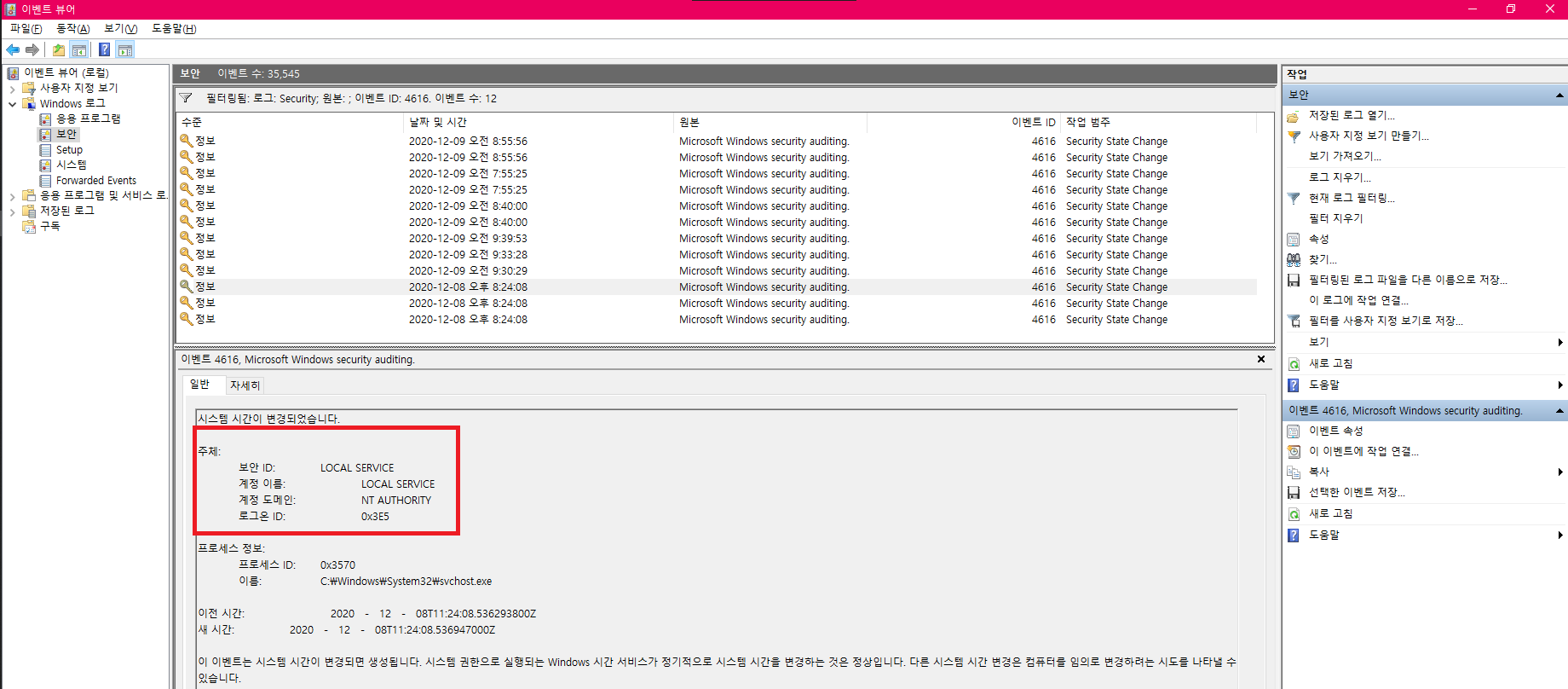
아래는 보안로그에서의 시간대 변경 로그이다.
Security이벤트 로그에서 확인 가능한 이벤트 아이디는 4616 이다. 해당 이벤트 로그의 주체를 보면 보안 ID와 이름은 LOCAL SERVICE로 동일하며, 계정 도메인은 NT AUTHORITY이다. 계정이름으로 LOCAL SERVICE를 생성한 적이 없으며, PC이름과 동일한 계정 도메인은 DESKTOP으로 시작하므로 이는 사용자가 수동으로 한 행위가 아니다. 즉, 이는 시스템이 자동적으로 시간 조정한 것임을 알 수 있다. 다음 아래 사진은 사용자가 시간대를 수동으로 변경한 로그이다.
해당 로그의 주체를 보면 보안 ID에는 PC이름과 계정이름이 적혀있고, 계정 이름에는 시스템 시간을 변경한 계정이름이 적혀있다. 또한, 계정 도메인은 PC의 이름이 들어가있다.
CASE2
표준시간대 변경
아래는 System 이벤트 로그에서 확인 가능한 시간변경 행위이다. 이벤트 아이디 22번인 표준 시간대 변경은 사용자가 직접 변경할 때만 나타난다. 그 외의 시스템이 자동으로 변경하는 내용은 없다.
여기서 중요한 점은 단순히 이벤트로그 1번으로는 사용자가 직접 시간을 바꾼 것인지 판단이 어렵다. 또한, 이벤트 아이디 1번의 이유는 첫 번째 System time synchronized with the hardware clock, 두 번째 An application or system component changed the time, 세 번째 System time adjusted to the new time zone. 총 세 가지 경우가 나온다. 세 번째의 경우는 22번 로그로 볼 수 있으니 제외시킬 수 있다. 그러면 System time synchronized with the hardware clock을 하는 것과, An application or system component changed the time로그를 보면 된다.
System time synchronized with the hardware clock경우
사용자가 아닌 시스템이 직접적으로 시간을 동기화하는 작업을 가진다. 다른 예로는 시스템이 저전원 상태에서 복귀될 때(절전모드에서 깨어날 때)에도 시스템 시간이 하드웨어 시간과 동기화한다.
An application or system component changed the time경우
하드웨어 시간과 시스템 시간이 다를 때 (초 단위 이하로 차이날 때) 시스템이 시간을 변경한다. 혹은 시간대가 다른 나라로 이동을 하였을 때도 변경이 될 여지로 보인다. 또한, 몇몇 PC는 절전모드 전환 후 복귀될 때 나타나기도 한다.
7040 이벤트를 보면 두 가지 경우가 보인다. 첫 번째로는 YY-MM-DD, HH:MM:SS 형식의 Windows Time 서비스, 두 번째로는 UTC +/- X의 표준시간대를 알 수 있다. 표준시간대 이벤트 로그는 위에 적었듯이 사용자가 수동으로 변경한 로그 외에는 시스템이 변경한 로그가 남지 않는다. 때문에 여기서 중점적으로 봐야할 것은 Windows Time 서비스의 시작 유형을 요청 시 시작인지, 사용 안 함 인지의 로그 판별이 중요하다. 기본적으로는 Windows Time서비스의 시작 유형은 요청 시 시작이 기본 설정 값이다. 또한, 요청 시 시작일 때는 수동으로 시간 변경이 불가능하다.
다시 말하면 자동으로 시간 설정이 꺼져 있으면 수동으로 날짜 및 시간 설정 변경이 가능해진다는 말이다. 즉, 7040이벤트 로그가 Windows Time 서비스가 요청 시 시작에서 사용 안 함으로 변경된 로그와 1번 로그(Application or system component changed the time)를 같이 보면 사용자가 시간을 변경했다고 의심할 수가 있다. 더 정확히 사용자가 시스템 시간을 직접 변경하였다라는 판단을 하기 위해서는 System 로그의 7040로그와, 1번로그 Security의 4616로그를 같이 확인해 주어야 한다.
System 로그의 7040에서 Windows Time 요청 시 시작을 사용 안 함과, 1번의 Appplication or system component changed the time과 Security의 4616 (계정 이름, 도메인 확인) 을 같이봐야 정확하게 사용자가 직접적으로 시스템 시간을 변경한 것인지의 유무를 판단할 수 있다.
FAT와 NTFS에 대해서 간단하게 알아보도록 합시다. 그 전에 앞서 부팅은 어떻게 되는 것일까?
부팅과정
MB
MBR(Master Boot Record)는 운영체제 부팅 시 POST(Power on Self-Test)과정을 마친 후 저장매체의 첫 번째 섹터를 호출하는 것으로 이 때 해당 부트 코드가 수행되게 한다. 부트 코드의 역할은 파티션 테이블에서 부팅 가능한 파티션을 찾아 해당 파티션의 부트 섹터를 호출해 주는 것인데, 부팅 가능한 파티션이 없을 경우 정의된 메시지를 출력하게 한다. 부팅가능한 파티션을 찾았을 경우 파티션 시작위치의 부트섹터를 로드한다. NTFS.sys 파일 시스템 드라이버가 있어야 해석이 가능하다.
파일 시스템?
파일 시스템이란 컴퓨터에서 파일이나 자료를 쉽게 발견 및 접근할 수 있도록 보관 또는 조직하는 체제를 가리키는 말이다. (위키백과)
파일 시스템의 종류에는 흔히들 알고 있는 FAT, NTFS, HFS, exFAT, ext2,3,4 등이 있다. 또한 더불어파티션이라는 개념을 알아야 한다. 파티션이란 물리적으로 하드디스크에 분할영역을 설정하는 것을 말하며 파티션이 없으면 비할당 영역이 되기 때문에 아무리 용량이 남아있더라 하더라도 사용할 수 없다. 운영체제가 최소한 한 개의 디스크가 할당 되어 있다는 것을 알아야 사용이 가능하기 때문이다.
실험결과 디스크 인식은 하나 사용은 불가능하다.
FAT란
파일 할당 테이블, FAT(File Allocation Table)
MS-DOS시절부터 사용
단순한 구조로 메모리카드, 디지털카메라, 플래시메모리 등에 널리 사용
FAT12, FAT16, FAT32. 뒤의 숫자는 표현 가능한 최대 클러스터 수를 말한다
최근 FAT의 단점을 보완하면서 FAT64(exFAT)가 등장했다
표현 가능한 최대 클러스터 수(FAT32 최대 클러스터수는 제한)볼륨 크기에 따른 클러스터 크기(FAT32)
exFAT(extend FAT)
윈도우 Embedded EC 6.0부터 사용
클러스터 표현 비트를 64bit로 확장
비트맵 사용
UTC 지원
시간 정밀도 10ns ( NTFS - 100ns )
FAT 기본 구조
예약된 영역 | FAT 영역 | 데이터 영역
NTFS란
FAT파일 시스템은 개인용 운영체제를 위해서 사용되었다. 윈도우 NT가 나오면서 서버용 파일 시스템이 필요로 하게 되었다. FAT방식보다 안정성, 확장성, 보안성 등이 강화되었으며, 2^64-1 클러스터를 가진다. 무엇보다 NTFS의 가장 큰 장점은 용량 관리가 효율적이라는 것이다. 즉, NTFS는 클러스터 단위를 사용한다.
아래의 표는 윈도우 히스토리이다.
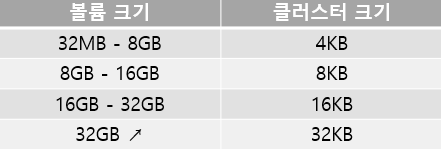
NTFS 클러스터 크기는 다음 표와 같다.
보통 사용하게 되면 4KB를 사용하게 된다. 다음은 NTFS에서 사용 가능한 파일 및 볼륨 크기이다.
- 저널링(Journaling) : 볼륨에 수행되는 모든 작업에 대해서 트랜잭션 단위로 기록함. Ext3와 같은 다른 파일시스템에도 적용됨
- ADS : NTFS는 다중 스트림을 지원한다. 즉, 하나의 파일이 하나 이상의 데이터를 담을 수 있다는 의미이다. 첫 번째 스트림에는 파일 내용이 있고, 두 번째 스트림에는 파일의 요약 정보 및 파일 아이콘 등 여러 정보를 담을 수 있다. 또한, 정보 은닉용도로 사용이 된다.
ADS 사용
- Sparse 파일 : 파일의 내용이 0으로 되어있을 경우 해당 파일의 내용을 그대로 볼륨에 저장하지 않고, 그 정보만을 유지하는 파일을 말한다. 예를 들어서 10MB의 파일의 맨 처음 4KB에만 의미 있는 데이터가 있고 나머지에는 전부 0으로 기록이 되어 있다면, 이 파일에는 의미있는 4KB만을 저장하고 나머지 영역이 0으로 채워져 있다는 정보만을 기록하게 된다. NTFS의 단점이기도 하다.
- Quotas : 디스크 쿼터. 사용자마다 디스크 사용량을 제한한다. NTFS는 다수의 사용자들이 하나의 컴퓨터를 쓰는 것으로 설계했다. 다른 사람이 디스크 용량을 사용하는 것을 막기 위해 관리자가 사용자들마다 개인 용량을 할당할 수 있게 했다.
- EFS : 파일을 FEK로 암호화한 후 이것을 사용자가 가진 공개키로 암호화하여 파일의 $EFS ADS에 저장한다. 복호화 할 때는 개인 키로 $EFS 스트림에 저장된 암호화된 FEK를 복호화한다. 그 다음으로 암호화가 풀린 FEK대칭 키로 파일을 복호화한다. 암/복호화가 NTFS 단계 아래에서 이루어지기 때문에 사용자와 프로그램은 암호화된 파일을 일반 파일 처럼 사용이 가능하다. NTFS5.0 부터 지원된다.
MFT(Master File Table) : NTFS는 정형화된 볼륨 레이아웃이 없고, 전체를 데이터 영역으로 관리한다. NFTS만 파싱함으로써 빠르게 파일 시스템을 분석할 수 있다. 파일이나 디렉토리가 많아질 수록 MFT 사이즈도 커진다. 삭제된 파일이나 디렉토리도 포함하기 때문에 사이즈가 줄어들지 않는다.